マルチコア ターゲットでの最適化と展開
このトピックでは、明示的な分割を使用して同時実行用に構成されたモデルを使用し、ターゲットに展開する方法について説明します。同時実行用にモデルを設定するには、同時実行用のモデルの構成を参照してください。ターゲット アーキテクチャを指定するには、ターゲット アーキテクチャの指定を参照してください。同時実行用に設定されたモデルで明示的な分割を使用するには、明示的な分割を使用したモデルの分割を参照してください。
コードの生成
同時実行用に構成されたモデルのコードを生成するには、Simulink® エディターの [アプリ] タブで [Simulink Coder] を選択します。[C コード] タブで、[ビルド] を選択します。結果として得られるコードは次のとおりです。
[同時実行] ダイアログ ボックスでタスクとトリガーにマッピングされるモデルの一部を表す C コード。C コードの生成には Simulink Coder™ ライセンスが必要です。詳細については、コード生成 (Simulink Coder)およびコード生成 (Embedded Coder)を参照してください。
[同時実行] ダイアログ ボックスでハードウェア ノードにマッピングされるモデルの一部を表す HDL コード。HDL コードの生成には HDL Coder™ ライセンスが必要です。詳細については、Simulink からの HDL コード生成 (HDL Coder)を参照してください。
同時実行タスクとトリガー間のデータ転送を処理し、ハードウェア コンポーネントとソフトウェア コンポーネントとのインターフェイスをとるコード。
生成された C コードには、システムで定義されたタスクまたはトリガーごとに 1 つの関数が含まれます。以下のように、タスクとトリガーによって関数の名前が決まります。
void <TriggerName>_TaskName(void);
このような各関数の内容は、次の場合を除き、ターゲットに依存しない C コードで構成されます。
ターゲット固有の機能を実装するブロックに対応するコード
カスタム ストレージ クラスから派生したものを含むカスタマイズ (Struct ストレージ クラスを使用してパラメーター データを構造体に整理する (Embedded Coder) 参照) または コード置換ライブラリ (Simulink Coder)
タスク間でのデータの転送方法を処理するために生成されるコード。特に、Simulink Coder は相互排除プリミティブとデータ同期セマフォのターゲット固有の実装を使用して、以下の疑似コード表で説明しているようにデータ転送を実装します。
| データ転送 | 初期化 | リーダー | ライター |
|---|---|---|---|
データの整合性のみ | BufferIndex = 0; Initialize Buffer[1] with IC | Begin mutual exclusion Tmp = 1 - BufferIndex; End mutual exclusiton Read Buffer[ Tmp ]; | Write Buffer[ BufferIndex ]; Begin mutual exclusion BufferIndex = 1 - BufferIndex; End mutual exclusion |
確定性を確保 (最大遅延) | WriterIndex = 0; ReaderIndex = 1; Initialize Buffer[1] with IC | Read Buffer[ ReaderIndex ]; ReaderIndex = 1 - ReaderIndex; | Write Buffer[ WriterIndex ] WriterIndex = 1 - WriterIndex; |
確定性を確保 (最小遅延) | N/A | Wait dataReady; Read data; Post readDone; | Wait readDone; Write data; Post dataReady; |
データの整合性のみ C-HDL インターフェイス | Simulink Coder 製品と HDL Coder 製品はどちらもターゲット固有の通信実装およびデバイスを使用して、ハードウェア コンポーネントとソフトウェア コンポーネント間のデータ転送を処理します。 | ||
生成された HDL コードにはハードウェア ノードごとに 1 つの HDL プロジェクトが含まれます。
デスクトップでのビルド
Simulink Coder および Embedded Coder® ターゲットは、Windows®、Linux® および macOS オペレーティング システム用のコードを生成するサンプルのターゲットを提供します。これは "ネイティブ スレッドの例" と呼ばれ、デスクトップ ターゲットへのモデルの展開に使用されています。デスクトップが最終ターゲットではない場合でも、別のターゲットに展開する前にモデルのプロファイルを作成して最適化するのに役立てることができます。
Embedded Coder ターゲットを指定した場合は、[コンフィギュレーション パラメーター] ダイアログ ボックスで次の変更を行います。
[コード生成] 、 [テンプレート] 、 [メイン プログラム例の生成] チェック ボックスをオンにします。
[コード生成] 、 [テンプレート] 、 [ターゲット オペレーティング システム] リストの
[NativeThreadsExample]を選択します。[OK] をクリックして変更を保存し、[コンフィギュレーション パラメーター] ダイアログ ボックスを閉じます。
モデル内のすべての参照モデルにこれらの設定を適用します。
モデルを設定したら、Ctrl-B を押してモデルをデスクトップにビルドし、展開します。ネイティブ スレッドの例では、ネイティブ スレッドの例で使用されるスレッド APIに示すように、Simulink Coder および Embedded Coder でターゲット固有のスレッド API とデータ管理プリミティブを使用する方法について説明します。同時に実行しているタスク間のデータ転送は、データ転送オプションに示すように動作します。コード生成製品は、ネイティブ スレッドの例で使用されるデータ保護と同期 APIに示すように、この動作がサポートされているターゲットで API を使用します。
ネイティブ スレッドの例で使用されるスレッド API
| 同時実行の側面 | Linux 実装 | Windows 実装 | macOS 実装 |
|---|---|---|---|
周期的なトリガー イベント | POSIX タイマー | Windows タイマー | 該当なし |
非周期的なトリガー イベント | POSIX リアルタイム信号 | Windows イベント | POSIX 非リアルタイム信号 |
非周期的トリガー | 非周期的タスクにマッピングされているブロックの場合: 信号待ちスレッド 非周期的トリガーにマッピングされているブロックの場合: 信号アクション | イベント待ちスレッド | 非周期的タスクにマッピングされているブロックの場合: 信号待ちスレッド 非周期的トリガーにマッピングされているブロックの場合: 信号アクション |
スレッド | POSIX® | Windows | POSIX |
スレッド優先順位 | サンプル時間に基づいて割り当て: 最速タスクに最高の優先順位 | 優先順位クラスは親プロセスから継承。 サンプル時間に基づいて割り当て: 最初の 3 つの最速タスクについては、最速タスクに最高の優先順位を割り当て。残りのタスクは最低の優先順位を共有。 | サンプル時間に基づいて割り当て: 最速タスクに最高の優先順位 |
オーバーラン検出の例 | あり | あり | なし |
ネイティブ スレッドの例で使用されるデータ保護と同期 API
| API | Linux 実装 | Windows 実装 | macOS 実装 |
|---|---|---|---|
| データ保護 API |
|
|
|
| 同期 API |
|
|
|
デスクトップでの明示的に分割されたモデルのプロファイルと評価
[同時実行] ダイアログ ボックスの [プロファイル レポート] ペインを使用して、マルチコア ターゲット上でコードの実行をプロファイリングします。Simulink Coder (GRT) および Embedded Coder (ERT) ターゲットを使用してプロファイリングを実行できます。プロファイリングを行うと、実行のボトルネックとなっている領域をモデル内で特定しやすくなります。各タスクの実行時間を分析して、実行時間の大半を占めているタスクを見つけることが可能です。たとえば、タスクの平均実行時間を比較できます。計算量の多いタスクやリアルタイム要件とオーバーランを満たしていないタスクがある場合は、計算量が少なく同時実行が可能なタスクにそのタスクを分割することができます。
プロファイル レポートを生成すると、ソフトウェアは以下の処理を実行します。
モデルを作成します。
モデルのコードを生成します。
データを収集する目的で、生成されたコードにツールを追加します。
生成されたコードをターゲット上で実行してデータを収集します。
データを照合し、現在のフォルダーに HTML ファイル (
model_name_ProfileReport.html) を生成して、[同時実行] ダイアログ ボックスの [プロファイル レポート] ペインに HTML ファイルを表示します。メモ
モデルの HTML プロファイル レポートが存在する場合、そのファイルが [プロファイル レポート] ペインに表示されます。新しいプロファイル レポートを生成するには、
 をクリックします。
をクリックします。
| セクション | 説明 |
|---|---|
概要 | 合計実行時間やプロファイル レポートの作成時間など、モデルの実行に関連する統計情報をまとめて表示します。ホスト マシン上のコア合計数も表示します。 |
Task Execution Time | タスク別に色分けされた円グラフに、各タスクの実行時間 (マイクロ秒単位) を表示します。 Windows、Linux、および macOS プラットフォームで表示されます。 |
Task Affinitization to Processor Cores | プラットフォームに依存します。タイム ステップおよびタスクごとに、Simulink はそのタイム ステップでタスクの実行が開始されたプロセッサ コア番号をプロセッサ別に色分けして表示します。 特定のタイム ステップにスケジューリングされたタスクが存在しない場合、 Windows および Linux プラットフォームで表示されます。 |
プロファイル レポートを解析したら、Model ブロックのマッピングを変更することにより、マルチコア システムで利用可能な同時実行性を効率的に利用することを検討してください (タスク、トリガー、ノードへのブロックのマッピングを参照)。
プロファイル レポートの生成
このトピックでは、同時実行に対してプロファイルできるようモデルを構成済みであることが前提になります。詳細については、同時実行用のモデルの構成を参照してください。
[同時実行] ダイアログ ボックスで [プロファイル レポート] ノードをクリックします。
プロファイル ツールは、
model_name_ProfileReport.htmlという名前のファイルを検索します。該当するファイルが現在のモデルに存在しない場合、[プロファイル レポート] ペインに以下のように表示されます。
メモ
モデルの HTML プロファイル レポートが存在する場合、そのファイルが [プロファイル レポート] ペインに表示されます。新しいプロファイル レポートを生成するには、
をクリックします。モデルの実行データをプロファイラーで収集する場合のタイム ステップの数を入力します。
[タスク実行のプロファイル レポートを生成します] ボタンをクリックします。
この操作により、モデルの作成、コードの生成、コードへのデータ収集ツールの追加、ターゲットでのコードの実行といった処理が行われて、HTML プロファイル レポートも生成されます。この処理には、数分かかることがあります。この処理が完了したら、プロファイル レポートの内容が [プロファイル レポート] ペインに表示されます。以下に例を示します。
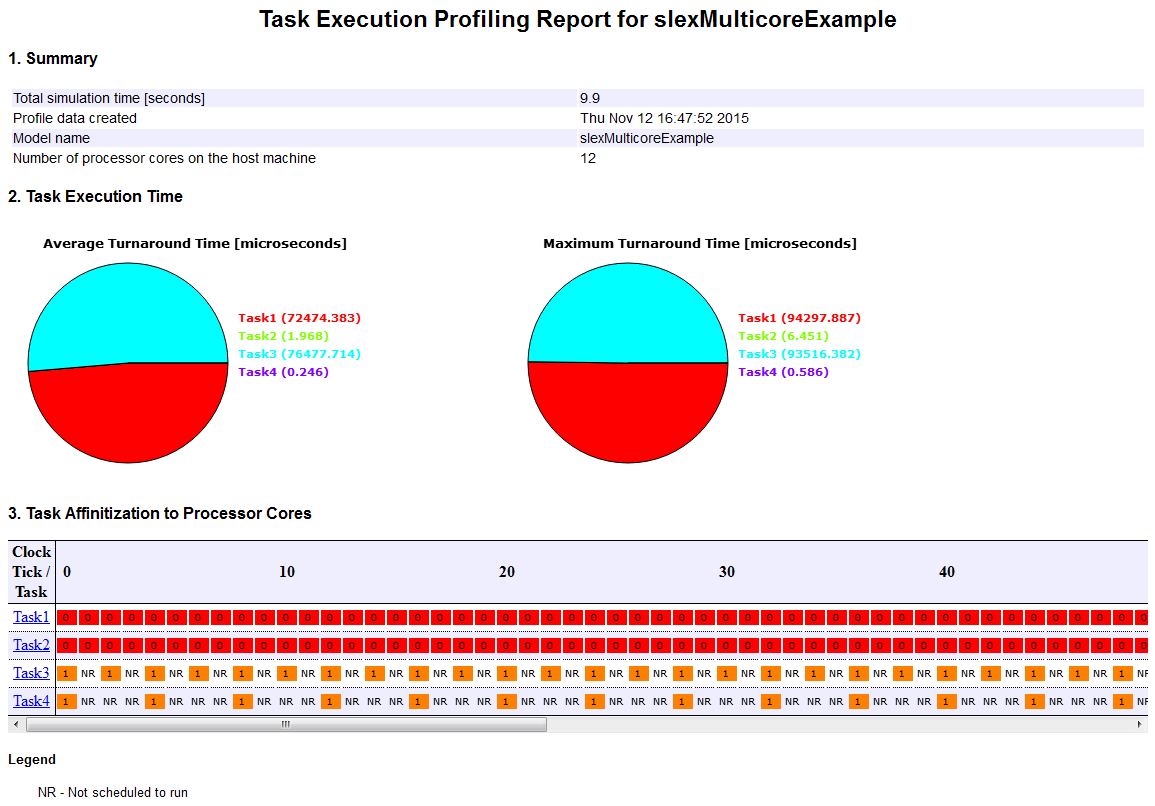
プロファイリング レポートには、概要、各タスクの実行時間、プロセッサ コアへの各タスクのマッピングが表示されます。タスク 1 とタスク 2 がコア 0 で実行され、タスク 3 とタスク 4 がコア 1 で実行されることがわかります。レポートの [Task Execution Time] セクションは、タスク 1 とタスク 3 の実行にかかる時間が最長であることを示しています。タスク 3 の周期はタスク 1 とタスク 2 の周期の 2 倍であり、タスク 4 の周期はタスク 3 の周期の 2 倍であることに注意してください。
プロファイル レポートを解析します。必要に応じてモデルまたはタスクのマッピングを作成および変更し、プロファイル レポートを再生成します。
コマンド ラインでのプロファイル レポートの生成. 別の方法として、同時実行に対して構成されたモデルのプロファイル レポートをコマンド ラインで生成できます。関数 Simulink.architecture.profile を使用します。
たとえば、モデル slexMulticoreSolverExample のプロファイル レポートを作成するには、以下の手順に従います。
openExample('slexMulticoreSolverExample');
Simulink.architecture.profile('slexMulticoreSolverExample');特定のサンプル数 (100) でモデル slexMulticoreSolverExample のプロファイル レポートを作成するには、以下のようにします。
Simulink.architecture.profile('slexMulticoreSolverExample',120);この関数は、slexMulticoreSolverExample_ProfileReport.html という名前のプロファイル レポートを現在のフォルダーに作成します。
生成された C コードのカスタマイズ
生成されたコードは、さまざまなアプリケーションおよび開発環境で利用できます。ニーズを満たすために、コードとツールのカスタマイズ (Embedded Coder)の説明に従って生成された C コードをカスタマイズします。これらのカスタマイズ機能に加え、マルチコア ターゲットと異種混合ターゲットの場合は、生成されたコードを次のようにさらにカスタマイズできます。
コード置換ライブラリを使用して、相互排除とデータ同期プリミティブの選択した実装を登録できます。
[同時実行] ダイアログ ボックスでタスクとトリガーに対してターゲット固有のプロパティを指定できるカスタム ターゲット アーキテクチャ ファイルを定義できます。詳細については、カスタム アーキテクチャ ファイルの定義を参照してください。
関連する例
詳細
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)