教師あり学習のワークフローとアルゴリズム
教師あり学習とは
教師あり機械学習の目的は、不確定要素が存在する状況で証拠に基づいて予測を行うモデルを構築することです。適応アルゴリズムでデータのパターンを識別するにつれて、コンピューターは観測から "学習" します。観測値の数が増えると、コンピューターの予測性能が向上します。
具体的には、教師あり学習アルゴリズムでは、既知の入力データのセットとそのデータに対する既知の応答 (出力) を使用して、新しいデータに対する応答を適切に予測するようにモデルを "学習" させます。
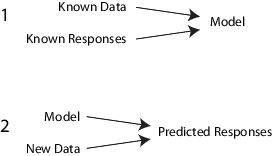
たとえば、誰かが 1 年以内に心臓発作を起こすかどうかを予測するとします。年齢、体重、身長、血圧など、過去の患者に関する一連のデータを利用できます。データを測定してから 1 年以内に過去の患者に心臓発作が起こったかどうかは既知の情報です。したがって、問題は既存のすべてのデータを結びつけて、ある人が 1 年以内に心臓発作を起こすかどうかを予測できるモデルを作成することになります。
入力データ全体は、異種混合成分から構成される行列と見なすことができます。この行列の行は "観測値"、"例" または "インスタンス" と呼ばれ、それぞれに被験者 (この例では患者) についての一連の測定値が格納されます。この行列の列は "予測子"、"属性" または "特徴量" と呼ばれ、それぞれは各被験者に対する測定値 (この例では年齢、体重、身長など) を表す変数です。応答データは、入力データ内の対応する観測値 (患者が心臓発作を起こしたかどうか) の出力が、各行に格納されている列ベクトルと見なすことができます。教師あり学習モデルを "近似" または "学習" させるには、適切なアルゴリズムを選択し、入力と応答データを渡します。
教師あり学習は、分類および回帰という 2 つのカテゴリに大別されます。
"分類" では、有限個のクラスの集合からクラス (または "ラベル") を観測値に割り当てることが目標です。つまり、応答はカテゴリカル変数です。応用例には、スパム フィルター、広告推奨システム、イメージと音声の認識などがあります。ある患者が 1 年以内に心臓発作を起こすかどうかを予測することは分類問題であり、可能なクラスは
trueとfalseです。通常、分類アルゴリズムはノミナルな応答値に適用されます。ただし、一部のアルゴリズムは順序クラスに対応できます (fitcecocを参照してください)。"回帰" では、観測値について連続的な測定値を予測することが目標です。つまり、応答変数は実数です。応用例には、株価、エネルギー消費、疾患の発生に関する予測などがあります。
Statistics and Machine Learning Toolbox™ の教師あり学習機能は、効率的なオブジェクト フレームワークから構成されています。さまざまなアルゴリズムの学習、モデルの結合によるアンサンブルの作成、モデルの性能の評価、交差検証、および新しいデータに対する応答の予測を効率的に行うことができます。
教師あり学習のステップ
Statistics and Machine Learning Toolbox には、教師あり学習に利用できるアルゴリズムが数多く用意されていますが、ほとんどの場合、予測モデルの取得には同じ基本的なワークフローを使用します。(アンサンブル学習の手順の詳しい説明は、アンサンブル学習のフレームワークを参照してください)。教師あり学習の手順は次のとおりです。
データの準備
どの教師あり学習手法でも、ここで通常 X と表記されている入力データ行列から開始されます。X の各行が、1 つの観測値を表します。X の各列が、1 つの変数または予測子を表します。X に存在する NaN 値で欠損値を表します。Statistics and Machine Learning Toolbox の教師あり学習アルゴリズムは、NaN 値を処理できますが、その値を無視するか、または NaN 値を含む行を無視するかのどちらかになります。
応答データ Y には、さまざまなデータ型を使用できます。Y の各要素は X の対応する行に対する応答を表します。Y データが欠落している観測値は無視されます。
回帰の場合、
YはXの行数と同じ数の要素をもつ数値ベクトルでなければなりません。分類の場合、
Yには、次の表に示す任意のデータ型を使用できます。この表では、欠損値を表現する方法も示しています。データ型 欠損値 数値ベクトル NaNcategorical ベクトル <undefined>文字配列 空白行 string 配列 <missing>または""文字ベクトルの cell 配列 ''logical ベクトル (表現できません)
アルゴリズムの選択
特性の異なるアルゴリズムには、それぞれ次のようなトレードオフが存在します。
学習の速度
メモリ使用量
新規データに関する予測精度
アルゴリズムによる予測の背景理解の容易さを表す、透明性または解釈可能性
アルゴリズムの詳細は、分類アルゴリズムの特性で説明します。アンサンブル アルゴリズムの詳細は、適用するアンサンブル集約法の選択で詳しく説明します。
モデルの近似
使用する近似関数は、選択したアルゴリズムによって異なります。
| アルゴリズム | 分類用の近似関数 | 回帰用の近似関数 |
|---|---|---|
| 決定木 | fitctree | fitrtree |
| 判別分析 | fitcdiscr | 該当なし |
| アンサンブル (ランダム フォレスト[1]など) | fitcensemble, TreeBagger | fitrensemble, TreeBagger |
| ガウス カーネル モデル | fitckernel (SVM 回帰とロジスティック回帰の学習器) | fitrkernel (SVM 回帰と最小二乗回帰の学習器) |
| ガウス過程回帰 (GPR) | 該当なし | fitrgp |
| 一般化加法モデル (GAM) | fitcgam | fitrgam |
| k 最近傍 | fitcknn | 該当なし |
| 線形モデル | fitclinear (SVM 回帰とロジスティック回帰) | fitrlinear (SVM 回帰と最小二乗回帰) |
| SVM または他の分類器向けのマルチクラス誤り訂正出力符号 (ECOC) モデル | fitcecoc | 該当なし |
| 単純ベイズ モデル | fitcnb | 該当なし |
| ニューラル ネットワーク モデル | fitcnet | fitrnet |
| サポート ベクター マシン (SVM) | fitcsvm | fitrsvm |
これらのアルゴリズムの比較については、分類アルゴリズムの特性を参照してください。
検証法の選択
近似した結果のモデルの精度を検査するには、主に次の 3 つの手法があります。
再代入誤差を調べます。以下の例を参照してください。
交差検証誤差を検査します。以下の例を参照してください。
バギングされた決定木の out-of-bag 誤差を検査します。以下の例を参照してください。
近似の検証とモデルの最終調整
モデルを検証した後で、精度や速度、メモリ使用率を向上させるために、パラメーターを変更したい場合があります。
精度の高いモデルが得られるように、近似パラメーターを変更します。以下の例を参照してください。
サイズの小さいモデルが得られるように、近似パラメーターを変更します。その結果、モデルの精度が向上する場合もあります。以下の例を参照してください。
別のアルゴリズムを試します。以下の説明を参照してください。
いずれかのタイプのモデルで満足のいく結果が得られたら、適切な関数 compact (分類木用の compact、回帰木用の compact、判別分析用の compact、単純ベイズ用の compact、SVM 用の compact、ECOC モデル用の compact、アンサンブル分類用の compact およびアンサンブル回帰用の compact) を使用してトリミングします。compact は予測に必要ない他のプロパティ (決定木の枝刈り情報など) と学習データをモデルから削除するので、メモリ使用量が少なくなります。kNN 分類モデルではラベルを予測するためにすべての学習データが必要なので、ClassificationKNN モデルのサイズを小さくすることはできません。
近似モデルを使用した予測
分類または回帰の応答値を予測するには、ほとんどの近似モデルで predict メソッドを使用します。
Ypredicted = predict(obj,Xnew)
objは、近似させたモデルまたはコンパクト モデルです。Xnewは、新しい入力データです。Ypredictedは予測応答値であり、分類または回帰のどちらかになります。
分類アルゴリズムの特性
以下の表では、さまざまな教師あり学習アルゴリズムの主な特性を示しています。特定のケースでは、リストされたものとは異なる特性を示す可能性があります。はじめにアルゴリズムを選択するときの指針として使用してください。速度、メモリ使用量、柔軟性および解釈可能性に関するトレードオフに基づいて判断してください。
ヒント
高速で解釈が容易なので、はじめは決定木または判別分析を試してください。応答を予測するにはモデルの精度が不十分な場合は、柔軟性が高い他の分類器を試してください。
柔軟性の制御については、各分類器のタイプの詳細を参照してください。過適合を回避するには、十分な精度が得られる柔軟性が低いモデルを探してください。
| 分類器 | マルチクラスのサポート | カテゴリカル予測子のサポート | 予測速度 | メモリ使用量 | 解釈可能性 |
|---|---|---|---|---|---|
決定木 — fitctree | あり | あり | 高 | 小 | 容易 |
判別分析 ― fitcdiscr | あり | なし | 高 | 線形の場合は小、二次の場合は大 | 容易 |
SVM ― fitcsvm | なし。fitcecoc を使用して複数のバイナリ SVM 分類器を結合 | あり | 線形の場合は中。 他の場合は低 | 線形の場合は中。 他のすべて: マルチクラスの場合は中、バイナリの場合は大 | 線形 SVM の場合は容易。 他のすべてのカーネル タイプの場合は困難 |
単純ベイズ ― fitcnb | あり | あり | 単純な分布の場合は中。 カーネル分布または高次元データの場合は低 | 単純な分布の場合は小。 カーネル分布または高次元データの場合は中 | 容易 |
最近傍 ― fitcknn | あり | あり | 3 次元の場合は低。 他の場合は中 | 中 | 困難 |
アンサンブル — fitcensemble および fitrensemble | あり | あり | アルゴリズムの選択によって高から中 | アルゴリズムの選択によって低から高 | 困難 |
この表の結果は、多くのデータ セットの分析に基づいています。調査に使用したデータ セットには、最大で 7000 個の観測値、80 個の予測子および 50 個のクラスが含まれています。以下のリストで、表の用語を定義します。
速度:
高 ― 0.01 秒
中 ― 1 秒
低 ― 100 秒
メモリ
小 ― 1MB
中 ― 4MB
大 ― 100MB
メモ
この表は、一般的な指針を示しています。データとマシンの速度によって、結果は異なります。
カテゴリカル予測子のサポート
次の表に、各分類器の予測子のデータ型サポートを示します。
| 分類器 | すべての予測子が数値 | すべての予測子がカテゴリカル | 一部が categorical、一部が数値 |
|---|---|---|---|
| 決定木 | あり | あり | あり |
| 判別分析 | あり | なし | なし |
| SVM | あり | あり | あり |
| 単純ベイズ | あり | あり | あり |
| 最近傍点 | ユークリッド距離のみ | ハミング距離のみ | なし |
| アンサンブル | あり | あり。ただし、判別分析分類器の部分空間アンサンブルは除く | あり。ただし、部分空間アンサンブルは除く |
誤分類コスト行列、事前確率、および観測値の重み
分類モデルに学習させるときに、名前と値の引数 Cost、Prior、および Weights を使用して、誤分類コスト行列、事前確率、および観測値の重みをそれぞれ指定できます。分類学習アルゴリズムのコストを考慮する学習と評価に指定した値が使用されます。
名前と値の引数 Cost、Prior、および Weights の指定
Cost を C、Prior を p、Weights を w と指定するとします。C、p、および w の値の形式は次のとおりです。
C は K 行 K 列の数値行列で、K はクラスの数です。cij = C(i,j) は、真のクラスが i である場合に観測値をクラス j に分類するコストです。
wj は観測値 j に対する観測値の重み、n は観測値の数です。
p は
1行 K 列の数値ベクトルで、pk はクラス k の事前確率です。Priorを"empirical"として指定した場合、pk はクラス k の観測値に対する観測値の重みの合計に設定されます。
分類モデルのプロパティ Cost、Prior、および W
Cost プロパティにはユーザー指定のコスト行列 (C) がそのまま格納され、Prior プロパティと W プロパティには正規化後の事前確率と観測値の重みがそれぞれ格納されます。
関数 fitcdiscr、fitcgam、fitcknn、fitcnb、または fitcnet で学習させた分類モデルでは、予測には Cost プロパティを使用しますが、学習には Cost を使用しません。したがって、モデルの Cost プロパティは読み取り専用ではなく、学習済みモデルの作成後にドット表記を使用してプロパティの値を変更できます。学習に Cost を使用するモデルの場合は、プロパティは読み取り専用になります。
事前確率は合計が 1 になるように正規化され、観測値の重みは合計がそれぞれのクラスの事前確率の値になるように正規化されます。
コストを考慮する学習
次の分類モデルでは、コストを考慮する学習がサポートされます。
fitctreeで学習させた分類決定木fitcensembleまたはTreeBaggerで学習させたアンサンブル分類fitckernelで学習させた SVM 回帰とロジスティック回帰の学習器のガウス カーネル分類fitcecocで学習させたマルチクラス誤り訂正出力符号 (ECOC) モデルfitclinearで学習させた SVM 回帰とロジスティック回帰の線形分類fitcsvmで学習させた SVM 分類
近似関数によるモデルの学習に、名前と値の引数 Cost で指定された誤分類コスト行列が使用されます。コストを考慮する学習の手法は分類器ごとに異なります。
fitcecocは、コスト行列と事前確率について、指定されたマルチクラス分類用の値をバイナリ学習器ごとのバイナリ分類用の値に変換します。詳細については、事前確率と誤分類コストを参照してください。fitctreeは、木を成長させるために平均コスト補正を適用します。fitcensemble、TreeBagger、fitckernel、fitclinear、およびfitcsvmは、指定されたコスト行列に応じて事前確率と観測値の重みを調整します。fitcensembleおよびTreeBaggerは、誤分類コストが大きいクラスをオーバーサンプリングし、誤分類コストが小さいクラスをアンダーサンプリングして、in-bag の標本を生成します。その結果、out-of-bag の標本では、誤分類コストが大きいクラスの観測値は少なくなり、誤分類コストが小さいクラスの観測値は多くなります。小さなデータ セットと歪みが大きいコスト行列を使用してアンサンブル分類を学習させる場合、クラスあたりの out-of-bag の観測値の数は非常に少なくなることがあります。そのため、推定された out-of-bag の誤差の変動幅が非常に大きくなり、解釈が困難になる場合があります。事前確率が大きいクラスでも同じ現象が発生する場合があります。
誤分類コスト行列に応じた事前確率と観測値の重みの調整. 関数 fitcensemble、TreeBagger、fitckernel、fitclinear、および fitcsvm では、モデルの学習用にクラスの事前確率 p が p*、観測値の重み w が w* に更新されて、コスト行列 C で指定されているペナルティが組み込まれます。
バイナリ分類モデルの場合、以下の手順が実行されます。
p を更新してコスト行列 C を組み込みます。
更新後の事前確率の合計が 1 になるように を正規化します。
事前確率がゼロのクラスに対応する観測値を学習データから削除します。
観測値が属するクラスの更新後の事前確率に合計が等しくなるように観測値の重み wj を正規化します。つまり、クラス k の観測値 j に対する正規化された重みは次のようになります。
重みがゼロの観測値を削除します。
fitcensemble または TreeBagger で学習させたアンサンブル モデルで 3 つ以上のクラスがある場合も、誤分類コスト行列に応じて事前確率が調整されます。この変換はさらに複雑です。ソフトウェアでは、まず、Zhou と Liu の[2]で説明されている行列方程式を解こうとします。解を求めるのに失敗した場合は、Breiman など[3]によって説明されている "平均コスト" を適用します。詳細については、Zadrozny 他[4]を参照してください。
コストを考慮する評価
コストを考慮する分析を実行することにより、分類モデルとデータ セットにおけるコストの不均衡を考慮できます。
関数
compareHoldoutまたはtestcholdoutを使用して、コストを考慮する検定を実行します。どちらの関数も、コスト行列を分析に含めることにより、2 つの分類モデルの予測性能を統計的に比較します。詳細については、コストを考慮する検定を参照してください。分類モデルのオブジェクト関数
loss、resubLoss、およびkfoldLossで返される観測誤分類コストを比較します。名前と値の引数LossFunを"classifcost"として指定します。これらの関数は、入力データ、学習データ、および交差検証用データの加重平均誤分類コストをそれぞれ返します。詳細については、いずれかの分類モデル オブジェクトのオブジェクト関数のリファレンス ページを参照してください。例については、Classification Lossを参照してください。
コストを考慮する評価の例については、コストを考慮して 2 つの分類モデルを比較するを参照してください。
参照
[1] Breiman, L. "Random Forests." Machine Learning 45, 2001, pp. 5–32.
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)