randomEffects
変量効果と関連する統計の推定
構文
説明
例
変量効果の推定と係数名の表示
標本データを読み込みます。
load carbigガロンあたりの走行マイル数 (MPG) の線形混合効果モデルを当てはめます。加速度と馬力は固定効果で、モデル年によってグループ化される切片と加速度については相関された変量効果の可能性があります。まず、データをテーブルに保存します。
tbl = table(Acceleration,Horsepower,Model_Year,MPG);
モデルを当てはめる。
lme = fitlme(tbl, 'MPG ~ Acceleration + Horsepower + (Acceleration|Model_Year)');変量効果係数の BLUP を計算し、対応する変量効果の名前を表示します。
[B,Bnames] = randomEffects(lme)
B = 26×1
3.1270
-0.2426
-1.6532
-0.0086
1.2075
-0.2179
4.4107
-0.4887
-1.3103
-0.0208
⋮
Bnames=26×3 table
Group Level Name
______________ ______ ________________
{'Model_Year'} {'70'} {'(Intercept)' }
{'Model_Year'} {'70'} {'Acceleration'}
{'Model_Year'} {'71'} {'(Intercept)' }
{'Model_Year'} {'71'} {'Acceleration'}
{'Model_Year'} {'72'} {'(Intercept)' }
{'Model_Year'} {'72'} {'Acceleration'}
{'Model_Year'} {'73'} {'(Intercept)' }
{'Model_Year'} {'73'} {'Acceleration'}
{'Model_Year'} {'74'} {'(Intercept)' }
{'Model_Year'} {'74'} {'Acceleration'}
{'Model_Year'} {'75'} {'(Intercept)' }
{'Model_Year'} {'75'} {'Acceleration'}
{'Model_Year'} {'76'} {'(Intercept)' }
{'Model_Year'} {'76'} {'Acceleration'}
{'Model_Year'} {'77'} {'(Intercept)' }
{'Model_Year'} {'77'} {'Acceleration'}
⋮
切片と加速度は、潜在的に相関性のある変量効果をもつため、車のモデル年でグループ化されます。また、randomEffects はグループ化変数の各水準において切片と加速度に個別の行を作成します。
変量効果の共分散パラメーターを計算します。
[~,~,stats] = covarianceParameters(lme)
stats=2×1 cell array
{3x7 classreg.regr.lmeutils.titleddataset}
{1x5 classreg.regr.lmeutils.titleddataset}
stats{1}ans =
COVARIANCE TYPE: FULLCHOLESKY
Group Name1 Name2 Type Estimate Lower Upper
Model_Year {'(Intercept)' } {'(Intercept)' } {'std' } 3.3475 1.2862 8.7119
Model_Year {'Acceleration'} {'(Intercept)' } {'corr'} -0.87971 -0.98501 -0.29675
Model_Year {'Acceleration'} {'Acceleration'} {'std' } 0.33789 0.1825 0.62558
相関値は、変量効果が負の相関関係に見えることを示しています。切片と加速度に対する変量効果をプロットし、これを確認します。
plot(B(1:2:end),B(2:2:end),'r*')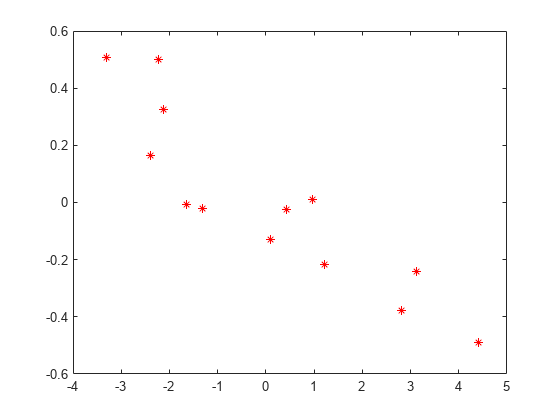
変量効果の推定値および関連する統計の計算
標本データを読み込みます。
load('fertilizer.mat');このデータセット配列には土壌の種類に基づいて土壌が 3 つのブロックに分けられている分割プロット試験のデータが含まれています。土壌の種類は砂質、シルトおよび粘土質です。各ブロックは 5 つのプロットに分割され、5 種類のトマトの苗木 (チェリー、エアルーム、グレープ、枝付き、プラム) がランダムにこれらのプロットに割り当てられます。その後、プロット内のトマトの苗木はサブプロットに分割され、それぞれのサブプロットが 4 つの肥料の中の 1 つにより処置されます。このデータは、シミュレーションされたものです。
実用目的でこのデータを ds という名前のデータセット配列に保存し、Tomato、Soil および Fertilizer をカテゴリカル変数として定義します。
ds = fertilizer; ds.Tomato = nominal(ds.Tomato); ds.Soil = nominal(ds.Soil); ds.Fertilizer = nominal(ds.Fertilizer);
線形混合効果モデルを当てはめます。Fertilizer および Tomato は固定効果変数であり、平均収穫量はブロック (土壌の種類) とブロック内のプロット (土壌の種類の中のトマトの種類) によって独立して変化します。
lme = fitlme(ds,'Yield ~ Fertilizer * Tomato + (1|Soil) + (1|Soil:Tomato)');変量効果の BLUP と関連する統計を計算します。
[~,~,stats] = randomEffects(lme)
stats =
RANDOM EFFECT COEFFICIENTS: DFMETHOD = 'RESIDUAL', ALPHA = 0.05
Group Level Name Estimate SEPred tStat DF pValue Lower Upper
{'Soil' } {'Loamy' } {'(Intercept)'} 1.0061 2.3374 0.43044 40 0.66918 -3.718 5.7303
{'Soil' } {'Sandy' } {'(Intercept)'} -1.5236 2.3374 -0.65181 40 0.51825 -6.2477 3.2006
{'Soil' } {'Silty' } {'(Intercept)'} 0.51744 2.3374 0.22137 40 0.82593 -4.2067 5.2416
{'Soil:Tomato'} {'Loamy Cherry' } {'(Intercept)'} 12.46 7.1765 1.7362 40 0.090224 -2.0443 26.964
{'Soil:Tomato'} {'Loamy Grape' } {'(Intercept)'} -2.6429 7.1765 -0.36827 40 0.71461 -17.147 11.861
{'Soil:Tomato'} {'Loamy Heirloom'} {'(Intercept)'} 16.681 7.1765 2.3244 40 0.025269 2.1766 31.185
{'Soil:Tomato'} {'Loamy Plum' } {'(Intercept)'} -5.0172 7.1765 -0.69911 40 0.48853 -19.522 9.4872
{'Soil:Tomato'} {'Loamy Vine' } {'(Intercept)'} -4.6874 7.1765 -0.65316 40 0.51739 -19.192 9.8169
{'Soil:Tomato'} {'Sandy Cherry' } {'(Intercept)'} -17.393 7.1765 -2.4235 40 0.019987 -31.897 -2.8882
{'Soil:Tomato'} {'Sandy Grape' } {'(Intercept)'} -7.3679 7.1765 -1.0267 40 0.31075 -21.872 7.1364
{'Soil:Tomato'} {'Sandy Heirloom'} {'(Intercept)'} -8.621 7.1765 -1.2013 40 0.23671 -23.125 5.8833
{'Soil:Tomato'} {'Sandy Plum' } {'(Intercept)'} 7.669 7.1765 1.0686 40 0.29165 -6.8353 22.173
{'Soil:Tomato'} {'Sandy Vine' } {'(Intercept)'} 0.28246 7.1765 0.039359 40 0.9688 -14.222 14.787
{'Soil:Tomato'} {'Silty Cherry' } {'(Intercept)'} 4.9326 7.1765 0.68732 40 0.49585 -9.5718 19.437
{'Soil:Tomato'} {'Silty Grape' } {'(Intercept)'} 10.011 7.1765 1.3949 40 0.17073 -4.4935 24.515
{'Soil:Tomato'} {'Silty Heirloom'} {'(Intercept)'} -8.0599 7.1765 -1.1231 40 0.2681 -22.564 6.4444
{'Soil:Tomato'} {'Silty Plum' } {'(Intercept)'} -2.6519 7.1765 -0.36952 40 0.71369 -17.156 11.852
{'Soil:Tomato'} {'Silty Vine' } {'(Intercept)'} 4.405 7.1765 0.6138 40 0.54282 -10.099 18.909
最初の 3 つの行には、グループ化変数 Soil の 3 つの水準 Loamy、Sandy および Silty の変量効果の推定と統計が含まれています。対応する 値 0.66918、0.51825 および 0.82593 は、これらの変量効果が 0 と有意には異ならないことを示します。続く 15 行には、切片について推定した変量効果の BLUP が含まれています。これらは、Soil で入れ子にされている変数 Tomato でグループ化されています (Tomato と Soil の交互作用)。
オプションを指定した信頼区間の計算
標本データを読み込みます。
load shiftシフトの時間によってパフォーマンスに有意差があるかどうかを評価するために、作業者別のランダムな切片をもつ線形混合効果モデルを当てはめます。制限付き最尤法を使用します。
lme = fitlme(shift,'QCDev ~ Shift + (1|Operator)');自由度の計算に残差オプションを使用して、変量効果に対する 99% の信頼区間を計算します。これは既定のメソッドです。
[~,~,stats] = randomEffects(lme,'Alpha',0.01)stats =
RANDOM EFFECT COEFFICIENTS: DFMETHOD = 'RESIDUAL', ALPHA = 0.01
Group Level Name Estimate SEPred tStat DF pValue Lower Upper
{'Operator'} {'1'} {'(Intercept)'} 0.57753 0.90378 0.63902 12 0.53482 -2.1831 3.3382
{'Operator'} {'2'} {'(Intercept)'} 1.1757 0.90378 1.3009 12 0.21772 -1.5849 3.9364
{'Operator'} {'3'} {'(Intercept)'} -2.1715 0.90378 -2.4027 12 0.033352 -4.9322 0.58909
{'Operator'} {'4'} {'(Intercept)'} 2.3655 0.90378 2.6174 12 0.022494 -0.39511 5.1261
{'Operator'} {'5'} {'(Intercept)'} -1.9472 0.90378 -2.1546 12 0.052216 -4.7079 0.81337
自由度の計算にサタースウェイトの近似法を使用して、変量効果に対する 99% の信頼区間を計算します。
[~,~,stats] = randomEffects(lme,'DFMethod','satterthwaite','Alpha',0.01)
stats =
RANDOM EFFECT COEFFICIENTS: DFMETHOD = 'SATTERTHWAITE', ALPHA = 0.01
Group Level Name Estimate SEPred tStat DF pValue Lower Upper
{'Operator'} {'1'} {'(Intercept)'} 0.57753 0.90378 0.63902 6.4253 0.5449 -2.684 3.839
{'Operator'} {'2'} {'(Intercept)'} 1.1757 0.90378 1.3009 6.4253 0.23799 -2.0858 4.4372
{'Operator'} {'3'} {'(Intercept)'} -2.1715 0.90378 -2.4027 6.4253 0.050386 -5.433 1.09
{'Operator'} {'4'} {'(Intercept)'} 2.3655 0.90378 2.6174 6.4253 0.037302 -0.89598 5.627
{'Operator'} {'5'} {'(Intercept)'} -1.9472 0.90378 -2.1546 6.4253 0.071626 -5.2087 1.3142
通常、サタースウェイト法では自由度 (DF) が小さい値になるので、変量効果の推定値に対する p 値 (pValue) と信頼区間 (Lower および Upper) が大きくなります。
入力引数
出力引数
バージョン履歴
R2013b で導入
参考
LinearMixedModel | fitlme | coefCI | coefTest | fixedEffects
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)