random
近似線形混合効果モデルからのランダム応答の生成
構文
説明
例
元の計画値でのランダム応答の生成
標本データを読み込みます。
load('fertilizer.mat');このデータセット配列には土壌の種類に基づいて土壌が 3 つのブロックに分けられている分割プロット試験のデータが含まれています。土壌の種類は砂質、シルトおよび粘土質です。各ブロックは 5 つのプロットに分割され、5 種類のトマトの苗木 (チェリー、エアルーム、グレープ、枝付き、プラム) がランダムにこれらのプロットに割り当てられます。その後、プロット内のトマトの苗木はサブプロットに分割され、それぞれのサブプロットが 4 つの肥料の中の 1 つにより処置されます。このデータは、シミュレーションされたものです。
実用目的でこのデータを ds という名前のデータセット配列に保存し、Tomato、Soil および Fertilizer をカテゴリカル変数として定義します。
ds = fertilizer; ds.Tomato = nominal(ds.Tomato); ds.Soil = nominal(ds.Soil); ds.Fertilizer = nominal(ds.Fertilizer);
線形混合効果モデルを当てはめます。Fertilizer および Tomato は固定効果変数であり、平均収穫量はブロック (土壌の種類) とブロック内のプロット (土壌の種類の中のトマトの種類) によって独立して変化します。
lme = fitlme(ds,'Yield ~ Fertilizer * Tomato + (1|Soil) + (1|Soil:Tomato)');元の計画点においてランダム応答値を生成します。最初の 5 つの値を表示します。
rng(123,'twister') % For reproducibility ysim = random(lme); ysim(1:5)
ans = 5×1
114.8785
134.2018
154.2818
169.7554
84.6089
無作為に生成した応答値と観測した応答値のプロット
標本データを読み込みます。
load carsmallWeight に対する固定効果と、Model_Year でグループ化されたランダム切片で、線形混合効果モデルを当てはめます。まず、データをテーブルに保存します。
tbl = table(MPG,Weight,Model_Year);
lme = fitlme(tbl,'MPG ~ Weight + (1|Model_Year)');元のデータを使用して応答をランダムに生成します。
rng(123,'twister') % For reproducibility ysim = random(lme,tbl);
元の応答と無作為に生成された応答をプロットして、相違点を確認します。それらをモデル年別にグループ化します。
figure() gscatter(Weight,MPG,Model_Year) hold on gscatter(Weight,ysim,Model_Year,[],'o+x') legend('70-data','76-data','82-data','70-sim','76-sim','82-sim') hold off
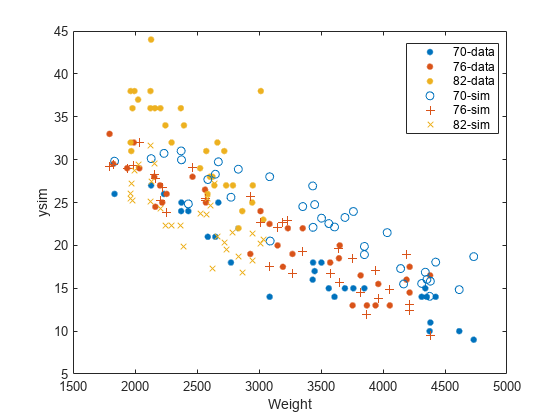
82 年に対してシミュレートされたランダム応答値が、その年の元のデータよりも低くなっています。これは、元のデータの推定変量効果よりも、82 年のシミュレートされた変量効果が低いことが原因である可能性があります。
新しいデータセット配列を使用した応答の生成
標本データを読み込みます。
load('fertilizer.mat');このデータセット配列には土壌の種類に基づいて土壌が 3 つのブロックに分けられている分割プロット試験のデータが含まれています。土壌の種類は砂質、シルトおよび粘土質です。各ブロックは 5 つのプロットに分割され、5 種類のトマトの苗木 (チェリー、エアルーム、グレープ、枝付き、プラム) がランダムにこれらのプロットに割り当てられます。その後、プロット内のトマトの苗木はサブプロットに分割され、それぞれのサブプロットが 4 つの肥料の中の 1 つにより処置されます。このデータは、シミュレーションされたものです。
実用目的でこのデータを ds という名前のデータセット配列に保存し、Tomato、Soil および Fertilizer をカテゴリカル変数として定義します。
ds = fertilizer; ds.Tomato = nominal(ds.Tomato); ds.Soil = nominal(ds.Soil); ds.Fertilizer = nominal(ds.Fertilizer);
線形混合効果モデルを当てはめます。Fertilizer および Tomato は固定効果変数であり、平均収穫量はブロック (土壌の種類) とブロック内のプロット (土壌の種類の中のトマトの種類) によって独立して変化します。
lme = fitlme(ds,'Yield ~ Fertilizer * Tomato + (1|Soil) + (1|Soil:Tomato)');計画値をもつ新しいデータセット配列を作成します。新しいデータセット配列は、モデル lme の近似に使用する元のデータセット配列と同じ変数をもたなければなりません。
dsnew = dataset();
dsnew.Soil = nominal({'Sandy';'Silty';'Silty'});
dsnew.Tomato = nominal({'Cherry';'Vine';'Plum'});
dsnew.Fertilizer = nominal([2;2;4]);新しい点でランダムな応答を生成します。
rng(123,'twister') % For reproducibility ysim = random(lme,dsnew)
ysim = 3×1
99.6006
101.9911
161.4026
新しい計画行列を使用したランダム応答の生成
標本データを読み込みます。
load carbigガロンあたりの走行マイル数 (MPG) の線形混合効果モデルを当てはめます。加速度、馬力、気筒数は固定効果で、モデル年によってグループ化される切片と加速度については相関された変量効果の可能性があります。
最初に、線形混合効果モデルを当てはめるための計画行列を準備します。
X = [ones(406,1) Acceleration Horsepower]; Z = [ones(406,1) Acceleration]; Model_Year = nominal(Model_Year); G = Model_Year;
次に、定義した計画行列とグループ化変数で fitlmematrix を使用してモデルを当てはめます。
lme = fitlmematrix(X,MPG,Z,G,'FixedEffectPredictors',.... {'Intercept','Acceleration','Horsepower'},'RandomEffectPredictors',... {{'Intercept','Acceleration'}},'RandomEffectGroups',{'Model_Year'});
応答値を予測する対象データを含む計画行列を作成します。Xnew は X のように 3 つの列をもたなければなりません。最初の列は 1 の列でなければなりません。また、最後の 2 列の値はそれぞれ Acceleration と Horsepower に一致しなければなりません。Znew の 1 列目は 1 の列でなければならず、2 列目には Xnew と同じ Acceleration 値が含まれなければなりません。G の元のグループ化変数はモデル年です。そのため、Gnew にはモデル年の値が含まれなければなりません。Gnew にはノミナル値が含まれていなければなりません。
Xnew = [1,13.5,185; 1,17,205; 1,21.2,193]; Znew = [1,13.5; 1,17; 1,21.2]; Gnew = nominal([73 77 82]);
新しい計画行列のデータに対するランダム応答を生成します。
rng(123,'twister') % For reproducibility ysim = random(lme,Xnew,Znew,Gnew)
ysim = 3×1
15.7416
10.6085
6.8796
次に、切片と加速度について変量効果が無相関な線形混合モデルに、同じ手順を繰り返します。最初に、元の変量効果計画と変量効果グループ化変数を変更します。次に、モデルを当てはめます。
Z = {ones(406,1),Acceleration};
G = {Model_Year,Model_Year};
lme = fitlmematrix(X,MPG,Z,G,'FixedEffectPredictors',....
{'Intercept','Acceleration','Horsepower'},'RandomEffectPredictors',...
{{'Intercept'},{'Acceleration'}},'RandomEffectGroups',{'Model_Year','Model_Year'});ここで、新しい変量効果計画 Znew およびグループ化変数計画 Gnew を再作成します。これらのどちらかを使用して応答値を予測します。
Znew = {[1;1;1],[13.5;17;21.2]};
MY = nominal([73 77 82]);
Gnew = {MY,MY};新しい計画行列を使用してランダム応答を生成します。
rng(123,'twister') % For reproducibility ysim = random(lme,Xnew,Znew,Gnew)
ysim = 3×1
16.8280
10.4375
4.1027
入力引数
出力引数
バージョン履歴
R2013b で導入
参考
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)