隠れマルコフ モデル (HMM)
隠れマルコフ モデル (HMM) の紹介
"隠れマルコフ モデル" (HMM) は、出力シーケンスを観測するモデルです。ただし、その出力を生成するためにモデルがたどった状態の系列はわかりません。隠れマルコフ モデルの分析は、観測されたデータから状態シーケンスを戻そうとします。
この例では、2 つの状態と 6 種類の可能な出力をもつマルコフ モデルを考えます。モデルは以下を使用します。
1 から 6 のラベルが付いた、6 つの面をもつ赤いサイコロ。
12 面をもち、そのうちの 5 つの面は 2 から 6 のラベルが付けられ、残りの 7 つの面は 1 とラベルが付けられている緑色のサイコロ。
表となる確率が .9 で、裏となる確率が .1 である、偏りのある赤いコイン。
表となる確率が .95 で、裏となる確率が .05 である、偏りのある緑色のコイン。
このモデルは、次の規則を使って、集合 {1、2、3、4、5、6} から数の列を作成します。
はじめに赤いサイコロを投げ、出た数を書き留めます。これが出力です。
赤いコインを投げ、次のいずれかを行います。
結果が表である場合、赤いサイコロを投げ、結果を書き留めます。
結果が裏である場合、緑色のサイコロを投げ、結果を書き留めます。
続く各ステップでは、前のステップで振ったサイコロと同じ色のコインを投げます。コインが表である場合、前のステップと同じサイコロを投げます。コインが裏である場合、もう一方のサイコロに変更します。
このモデルに対する状態図は、次の図に示すように 2 つの状態をもちます。
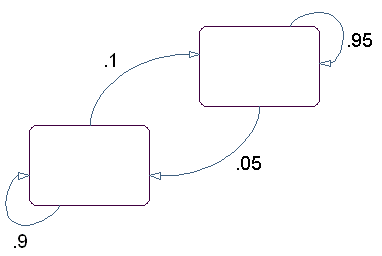
状態と同じ色のサイコロを投げることによって、ある状態からの出力を決めます。状態と同じ色のコインを投げることによって、次の状態への遷移を決めます。
遷移行列は次のようになります。
出力行列は次のようになります。
コインとサイコロの色から状態シーケンスを知ることができるため、モデルの状態は隠されていません。しかし、サイコロやコインを見せずに、誰かが出力を生成していると仮定してください。見ることができるのは、出力シーケンスのみです。他の数に比べ 1 をより多く見始めた場合、モデルは緑色の状態にあるのではないかと思うかもしれませんが、投げられているサイコロの色を見ることはできないので確信はもてません。
隠れマルコフ モデルは、以下の疑問を提起します。
出力シーケンスが与えられた場合に、最も可能性のある状態経路は何でしょうか。
出力シーケンスが与えられると、どのようにしてモデルの遷移とモデルの出力の確率を推定できるでしょうか。
モデルが、与えられたシーケンスを生成する "事前確率" とは何でしょうか。
シーケンスの任意の点において、モデルが特定の状態にある "事後確率" とは何でしょうか。
隠れマルコフ モデルの分析
隠れマルコフ モデルに関連する Statistics and Machine Learning Toolbox™ 関数は以下のとおりです。
hmmgenerate― マルコフ モデルから状態および出力シーケンスを生成しますhmmestimate― 出力シーケンスと既知の状態シーケンスから、遷移確率と出力確率の最尤推定値を計算しますhmmtrain― 出力シーケンスから、遷移確率と出力確率の最尤推定値を計算しますhmmviterbi― 隠れマルコフ モデルについて、最も確からしい状態経路を計算しますhmmdecode― 出力シーケンスの事後状態確率を計算します
この節では、隠れマルコフ モデルを解析するためのこれらの関数の使用方法を説明します。
テスト シーケンスの生成
以下のコマンドは、隠れマルコフ モデル (HMM) の紹介で説明したモデルに対する遷移行列と出力行列を作成します。
TRANS = [.9 .1; .05 .95]; EMIS = [1/6, 1/6, 1/6, 1/6, 1/6, 1/6;... 7/12, 1/12, 1/12, 1/12, 1/12, 1/12];
このモデルからランダムな状態シーケンスと出力シーケンスを生成するには、hmmgenerate を使用します。
[seq,states] = hmmgenerate(1000,TRANS,EMIS);
出力 seq が、出力 (emission) のシーケンスであり、出力 states は状態シーケンスです。
hmmgenerate は、ステップ 0 で状態 1 ではじまり、ステップ 1 で状態 i1 への遷移を行い、states の最初の要素として i1 を出力します。初期状態を変更するには、初期状態分布の変更を参照してください。
状態シーケンスの推定
遷移行列 TRANS と出力行列 EMIS が与えられると、関数 hmmviterbi は、Viterbi アルゴリズムを使用して、出力の与えられた列 seq を作成するために、そのモデルがたどると考えられる最も確からしい状態シーケンスを計算します。
likelystates = hmmviterbi(seq, TRANS, EMIS);
likelystates は、seq と同じ長さの列です。
hmmviterbi の正確さをテストするために、列 likelystates と一致する実際の列の states のパーセンテージを計算します。
sum(states==likelystates)/1000 ans = 0.8200
この場合、最も確からしい状態シーケンスは、ランダムな列の 82% に一致します。
遷移行列と出力行列の推定
関数 hmmestimate と hmmtrain は、出力シーケンス seq が与えられると、遷移行列 TRANS と出力行列 EMIS を推定します。
hmmestimate の使用. 関数 hmmestimate を使用するには、このモデルが seq を生成するために通過してきた状態シーケンス states がわかっている必要があります。
以下は、出力および状態のシーケンスを取り、遷移行列および出力行列の推定を出力します。
[TRANS_EST, EMIS_EST] = hmmestimate(seq, states) TRANS_EST = 0.8989 0.1011 0.0585 0.9415 EMIS_EST = 0.1721 0.1721 0.1749 0.1612 0.1803 0.1393 0.5836 0.0741 0.0804 0.0789 0.0726 0.1104
出力を、オリジナルの遷移行列 TRANS と出力行列 EMIS と比較できます。
TRANS TRANS = 0.9000 0.1000 0.0500 0.9500 EMIS EMIS = 0.1667 0.1667 0.1667 0.1667 0.1667 0.1667 0.5833 0.0833 0.0833 0.0833 0.0833 0.0833
hmmtrain の使用. 状態シーケンス states が未知ではあるが TRANS と EMIS の初期推定がある場合、hmmtrain を使用して TRANS と EMIS を推定できます。
TRANS および EMIS に対する初期推定をもつとします。
TRANS_GUESS = [.85 .15; .1 .9]; EMIS_GUESS = [.17 .16 .17 .16 .17 .17;.6 .08 .08 .08 .08 08];
以下のように、TRANS および EMIS を推定します。
[TRANS_EST2, EMIS_EST2] = hmmtrain(seq, TRANS_GUESS, EMIS_GUESS) TRANS_EST2 = 0.2286 0.7714 0.0032 0.9968 EMIS_EST2 = 0.1436 0.2348 0.1837 0.1963 0.2350 0.0066 0.4355 0.1089 0.1144 0.1082 0.1109 0.1220
hmmtrain は、各ステップで調整された行列が観測される系列 行列 seq を生成する可能性がより高くなるように、行列 TRANS_GUESS と EMIS_GUESS を変更する反復アルゴリズムを使用します。アルゴリズムは、連続する 2 回の繰り返しでの行列が互いに 小さい許容誤差内に入ると停止します。
アルゴリズムが最大反復回数 (既定値は 100) 内でこの許容誤差に達しない場合、アルゴリズムは停止します。この場合 hmmtrain は、TRANS_EST と EMIS_EST の最終値を返し、許容誤差に到達していないという警告を発します。
アルゴリズムが指定する許容誤差に達しない場合、次のコマンドを使用して最大反復回数の既定値を大きくします。
hmmtrain(seq,TRANS_GUESS,EMIS_GUESS,'maxiterations',maxiter)
ここで、maxiter はアルゴリズムが実行する最大のステップ数です。
次のコマンドを使用して、許容誤差の既定値を変更します。
hmmtrain(seq, TRANS_GUESS, EMIS_GUESS, 'tolerance', tol)
ここで、tol は指定する許容誤差値です。tol の値が大きくなると、アルゴリズムはより迅速に停止しますが、結果の精度は下がります。
hmmtrain の出力行列の信頼性をより低くする 2 つの要因が存在します。
アルゴリズムが、真の遷移行列と出力行列を表さない局所的最大値に収束する場合。このことが当てはまると思われる場合は、行列
TRANS_ESTおよびEMIS_ESTに対して別の初期推定を使用してください。列
seqが短すぎて行列を適切に学習できない可能性がある場合。これに当てはまると思われる場合、seqとしてより長い列を使用してください。
事後状態確率の計算
出力シーケンス seq の事後状態確率は、seq が出力される場合、モデルが seq にシンボルを生成するときに、ある特定の状態にある条件付き確率です。hmmdecode を使用して事後状態確率を計算することができます。
PSTATES = hmmdecode(seq,TRANS,EMIS)
出力 PSTATES は M 行 L 列の行列です。ここで、M は状態の数であり、L は seq の長さです。PSTATES(i,j) は、seq が出力される場合、seq の j 番目のシンボルを生成するときにモデルが状態 i にある条件付き確率です。
hmmdecode は、最初の出力の前に、ステップ 0 で状態 1 にあるモデルから開始します。PSTATES(i,1) は、モデルが次のステップ 1 で状態 i になる確率です。初期状態を変更するには、初期状態分布の変更を参照してください。
列 seq の確率の対数を出力するには、hmmdecode の 2 番目の出力引数を使用します。
[PSTATES,logpseq] = hmmdecode(seq,TRANS,EMIS)
列の確率は、列の長さが増すにつれて 0 になる傾向があります。そのため、十分長い列の確率は、コンピューターが表すことができる最小の正の数よりも小さくなります。hmmdecode は、この問題を回避するために、確率の対数を出力します。
初期状態分布の変更
既定では、Statistics and Machine Learning Toolbox の隠れマルコフ モデル関数は状態 1 で始まります。言い換えると、初期状態の分布では、すべての確率質量が状態 1 に集中しています。別の確率分布 p = [p1, p2, ..., pM] を M 個の初期状態に割り当てるには、次の手順を実行します。
次のような形式の M+1-by-M+1 列に拡張した遷移行列 を作成します。
ここで、T は真の遷移行列です。 の 1 列目には M+1 個のゼロが含まれています。p の合計は 1 でなければなりません。
次のような形式の M+1 行 N 列に拡張した出力行列 を作成します。
遷移行列と出力行列がそれぞれ TRANS および EMIS である場合、次のコマンドを使用して 拡張された行列を作成します。
TRANS_HAT = [0 p; zeros(size(TRANS,1),1) TRANS]; EMIS_HAT = [zeros(1,size(EMIS,2)); EMIS];
参考
hmmdecode | hmmestimate | hmmgenerate | hmmtrain | hmmviterbi
関連するトピック
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)