anova2
2 因子 ANOVA
説明
anova2 は、平衡な設計で 2 因子分散分析 (ANOVA) を実行します。不平衡な設計で 2 因子 ANOVA を実行する方法については、anovan を参照してください。
p = anova2(y,reps,displayopt)displayopt が 'on' (既定値) の場合は表示、displayopt が 'off' の場合は非表示になる ANOVA 表の表示を有効にします。
例
2 因子 ANOVA
標本データを読み込みます。
load popcorn
popcornpopcorn = 6×3
5.5000 4.5000 3.5000
5.5000 4.5000 4.0000
6.0000 4.0000 3.0000
6.5000 5.0000 4.0000
7.0000 5.5000 5.0000
7.0000 5.0000 4.5000
このデータは、ポップコーンのブランドと製造器具タイプに関する研究 (Hogg 1987) によるものです。行列 popcorn の各列は Gourmet、National および Generic というブランドに対応しています。行は製造器具のタイプ (オイルとエアー) です。この研究では、製造器具ごとに異なるブランドのポップコーンを 3 回ずつ作りました。つまり、反復数は 3 です。初めの 3 行はオイル タイプの製造器具、最後の 3 行はエアー タイプの製造器具に対応しています。応答値は、出来上がったポップコーンのカップ数です。
2 因子 ANOVA を実行します。簡単に結果を利用できるようにするため、ANOVA 表を cell 配列 tbl に格納します。
[p,tbl] = anova2(popcorn,3);

Prob>F の列には p 値が示されており、それぞれ 3 つのポップコーン ブランド (0.0000)、2 つの製造器具タイプ (0.0001)、ブランドと製造器具タイプの交互作用 (0.7462) に対応しています。これらの値から、ポップコーン ブランドと製造器具タイプは出来上がるポップコーンの量に影響を与えるが、これらの間の交互作用効果を示す証拠はないことがわかります。
ANOVA 表が含まれている cell 配列を表示します。
tbl
tbl=6×6 cell array
{'Source' } {'SS' } {'df'} {'MS' } {'F' } {'Prob>F' }
{'Columns' } {[15.7500]} {[ 2]} {[ 7.8750]} {[ 56.7000]} {[7.6790e-07]}
{'Rows' } {[ 4.5000]} {[ 1]} {[ 4.5000]} {[ 32.4000]} {[1.0037e-04]}
{'Interaction'} {[ 0.0833]} {[ 2]} {[ 0.0417]} {[ 0.3000]} {[ 0.7462]}
{'Error' } {[ 1.6667]} {[12]} {[ 0.1389]} {0x0 double} {0x0 double }
{'Total' } {[ 22]} {[17]} {0x0 double} {0x0 double} {0x0 double }
因子および因子間の交互作用の F 統計量を、別個の変数に格納します。
Fbrands = tbl{2,5}Fbrands = 56.7000
Fpoppertype = tbl{3,5}Fpoppertype = 32.4000
Finteraction = tbl{4,5}Finteraction = 0.3000
2 因子 ANOVA の多重比較
標本データを読み込みます。
load popcorn
popcornpopcorn = 6×3
5.5000 4.5000 3.5000
5.5000 4.5000 4.0000
6.0000 4.0000 3.0000
6.5000 5.0000 4.0000
7.0000 5.5000 5.0000
7.0000 5.0000 4.5000
このデータは、ポップコーンのブランドと製造器具タイプに関する研究 (Hogg 1987) によるものです。行列 popcorn の列はブランド (Gourmet、National、および Generic) を示しています。行は製造器具のタイプ (オイルとエアー) です。初めの 3 行はオイル タイプの製造器具、最後の 3 行はエアー タイプの製造器具に対応しています。この研究では、各製造器具で各ブランドのポップコーンを 3 回ずつ作りました。値は、ポップコーンの生産量をカップ単位で示しています。
2 因子 ANOVA を実行します。主効果について多重比較検定を実行するために必要な統計量も計算します。
[~,~,stats] = anova2(popcorn,3,"off")stats = struct with fields:
source: 'anova2'
sigmasq: 0.1389
colmeans: [6.2500 4.7500 4]
coln: 6
rowmeans: [4.5000 5.5000]
rown: 9
inter: 1
pval: 0.7462
df: 12
構造体 stats には次の情報が含まれています。
平均二乗誤差 (
sigmasq)各ポップコーン ブランドの平均生産量の推定値 (
colmeans)各ポップコーン ブランドの観測数 (
coln)各製造器具タイプの平均生産量の推定値 (
rowmeans)各製造器具タイプの観測数 (
rown)交互作用の数 (
inter)交互作用項の有意水準を示す p 値 (
pval)誤差自由度 (
df)
多重比較検定を実行して、出来上がるポップコーンの量がポップコーン ブランド (列) のペア間で異なるかどうかを調べます。
c1 = multcompare(stats);
Note: Your model includes an interaction term. A test of main effects can be difficult to interpret when the model includes interactions.
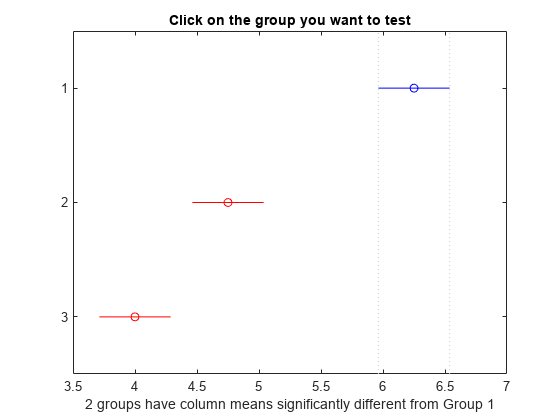
図には、平均の多重比較が示されています。既定では、グループ 1 の平均が強調表示され、比較区間が青になります。他の 2 つのグループの比較区間は、グループ 1 の平均の区間と重なっていないので、赤で強調表示されています。区間が重なっていないことから、どちらの平均もグループ 1 の平均と異なることがわかります。他のグループの平均を選択して、すべてのグループの平均が他と有意に異なることを確認します。
多重比較の結果を table で表示します。
tbl1 = array2table(c1,"VariableNames", ... ["Group A","Group B","Lower Limit","A-B","Upper Limit","P-value"])
tbl1=3×6 table
Group A Group B Lower Limit A-B Upper Limit P-value
_______ _______ ___________ ____ ___________ __________
1 2 0.92597 1.5 2.074 4.1188e-05
1 3 1.676 2.25 2.824 6.1588e-07
2 3 0.17597 0.75 1.324 0.011591
c1 の初めの 2 列には、比較したグループが示されています。4 列目には、推定したグループ平均の間の差が示されています。3 列目と 5 列目には、真の平均の差に関する 95% 信頼区間の下限と上限が示されています。6 列目には、対応する平均の差がゼロに等しいという仮説を検定するための p 値が含まれています。すべての "p" 値が非常に小さいので、3 つのブランドすべてででき上がるポップコーンの量が異なることがわかります。
多重比較検定を実行して、出来上がるポップコーンの量が 2 種類の製造器具タイプ (行) の間で異なるかどうかを調べます。
c2 = multcompare(stats,"Estimate","row");
Note: Your model includes an interaction term. A test of main effects can be difficult to interpret when the model includes interactions.

tbl2 = array2table(c2,"VariableNames", ... ["Group A","Group B","Lower Limit","A-B","Upper Limit","P-value"])
tbl2=1×6 table
Group A Group B Lower Limit A-B Upper Limit P-value
_______ _______ ___________ ___ ___________ __________
1 2 -1.3828 -1 -0.61722 0.00010037
"p" 値が小さいので、でき上がるポップコーンの量は 2 つの製造器具タイプ (エアーとオイル) で異なることがわかります。図には同じ結果が示されています。比較区間が重なっていないので、グループの平均が互いに有意に異なることがわかります。
入力引数
出力引数
代替機能
anova2 を使用する代わりに、関数 anova を使用して anova オブジェクトを作成できます。関数 anova には次の利点があります。
関数
anovaでは、ANOVA モデルのタイプ、二乗和のタイプ、カテゴリカルとして扱う因子を指定できます。anovaでは、table の予測子と応答の入力引数もサポートされます。anovaオブジェクトのプロパティには、anova2で返される出力に加えて以下が含まれます。ANOVA モデルの式
当てはめられる ANOVA モデルの係数
残差
因子と応答データ
anovaオブジェクトを当てはめた後に、anovaのオブジェクト関数を使用して追加の解析を実行できます。たとえば、ANOVA の平均の多重比較についての対話型プロットを作成したり、因子の各値の平均応答推定を取得したり、分散成分推定を計算したりできます。
参照
[1] Hogg, R. V., and J. Ledolter. Engineering Statistics. New York: MacMillan, 1987.
バージョン履歴
R2006a より前に導入
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)