データの選択
Curve Fitting Toolbox™ には、曲線や曲面をデータに当てはめる方法が 2 つあります。コマンド ラインで関数 fit を使用して近似を作成するか、曲線フィッター アプリを使用して対話的に近似を作成できます。どちらの方法でも、曲線または曲面を当てはめる前にデータを選択する必要があります。曲線近似では、Y のデータを選択する必要があり、オプションで X のデータを選択できます。曲面近似では、X、Y、および Z のデータを選択する必要があります。
ワークスペースへのデータのインポート
データを選択する前に、そのデータを MATLAB® ワークスペース変数にインポートする必要があります。標準ファイル形式に記載された関数を使用して、サンプル データをインポートするかファイルからデータをインポートできます。
コマンド ラインでの近似対象データの選択
コマンド ラインでデータを選択するには、近似プロセスで関数 fit にデータを渡します。
曲線近似のデータを選択するには、X と Y のデータを同じ行数の列ベクトルとして保存します。その後、それらの列ベクトルを関数
fitに入力引数xおよびyとして渡します。曲面近似のデータを選択するには、次のいずれかを行います。
X、Y、および Z のデータを同じサイズの列ベクトルとして保存します。その後、それらのベクトルを関数
fitに入力引数x、y、およびzとして渡します。X と Y のデータを 2 列の配列として保存します。その配列と同じ行数の列ベクトルとして Z のデータを保存します。それらの配列とベクトルを関数
fitに入力引数xおよびyとしてそれぞれ渡します。
コマンド ラインでデータに曲線を当てはめる例については、2 次曲線による近似を参照してください。コマンド ラインでデータに曲面を当てはめる例については、多項式曲面による近似を参照してください。
曲線フィッター アプリでの近似対象データの選択
データを対話的に選択するには、[アプリ] タブをクリックしてアプリ ギャラリーを表示し、[数学、統計および最適化] セクションで曲線フィッターを選択します。[曲線フィッター] タブの [データ] セクションで [データの選択] をクリックします。
曲線フィッター アプリでは、選択したデータのスナップショットが使用されます。ワークスペースで後からデータを変更しても近似には影響しません。当てはめたデータをワークスペースから更新するには、最初に変数の選択を変更してから、ドロップダウン コントロールで変数を再度選択します。
曲線近似のデータの選択
曲線近似のデータを選択するには、Y のデータをベクトル、table 変数、または配列としてインポートします。X のデータがある場合は、そのデータをベクトル、table 変数、または配列としてインポートします。X と Y の要素数は同じでなければなりません。その後、次のいずれかを行います。
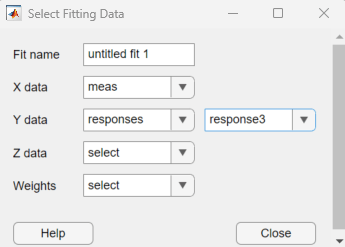
[近似データの選択] ダイアログ ボックスで、[X データ] および [Y データ] のメニューを使用して変数を選択します。table 変数に格納されたデータを選択するには、テーブル名を選択して 2 番目のメニューを右に表示します。その後、2 番目のメニューから table 変数を選択します。
変数 Y をそのインデックスに対してプロットするには、変数 Y のみを [Y データ] メニューから選択します。
次に示す [近似データの選択] ダイアログ ボックスでは、[X データ] としてベクトル変数が選択され、[Y データ] として table 変数が選択されています。
同様に、ワークスペースの任意の数値変数を選択して (数値テーブル列も可能) [重み] として使用することができます。重みを指定する場合、重みの変数は他のデータ変数と同じ数の要素を含んでいなければなりません。
曲線フィッター アプリで曲線および曲面を当てはめる例については、対話型の曲線近似および曲面近似を参照してください。
曲面近似のデータの選択
曲面近似のデータを選択するには、X、Y、および Z のデータのそれぞれをベクトル、table 変数、または配列として保存します。次の条件のいずれかを満たさなければなりません。
変数 X、Y、および Z の要素数が同じである。
メモ
曲線フィッター アプリでは、各データ変数はサイズが同じであると想定されています。サイズが異なっているが要素数が同じ場合、アプリは変数を再構築して近似を作成し、[結果] ペインに警告を表示します。
変数 X が n 要素を含むベクトル、変数 Y が m 要素を含むベクトル、変数 Z が m 行 n 列の行列である。この場合、Y のデータと X のデータがそれぞれテーブルの行と列のヘッダーとして扱われます。詳細については、表形式データを参照してください。
メモ
変数
Zが n 行 m 列の行列の場合、アプリはZを転置して近似を作成し、[結果] ペインにデータ変換に関する警告を表示します。
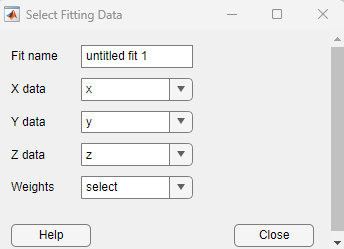
[近似データの選択] ダイアログ ボックスで、[X データ]、[Y データ]、および [Z データ] のメニューを使用して変数を選択します。テーブルに保存された変数を選択するには、テーブル名を選択して 2 番目のメニューを右に表示します。その後、2 番目のメニューから table 変数を選択します。
次に示す [近似データの選択] ダイアログ ボックスでは、[X データ]、[Y データ]、および [Z データ] としてベクトル変数が選択されています。
同様に、ワークスペースの任意の数値変数を選択して (数値テーブル列も可能) [重み] として使用することができます。重みを指定する場合、重みの変数は変数 Z と同じ数の要素を含んでいなければなりません。
曲線フィッター アプリを使用して曲線および曲面を当てはめる例については、対話型の曲線近似および曲面近似を参照してください。
表形式データ
データ変数は表形式データを形成できます。この場合、Y のデータと X のデータはテーブルの行ヘッダーと列ヘッダー ("ブレークポイント" とも呼ばれる) をそれぞれ表し、Z のデータにテーブルの値が格納されます。
サイズに互換性があるのは、次のすべての条件を満たす場合です。
X のデータが長さ
nのベクトルに保存されている。Y のデータが長さ
mのベクトルに保存されている。Z のデータがサイズ
[m,n]の行列に保存されている。
次の表に、n = 4 および m = 3 の表形式データの例を示します。
x(1) | x(2) | x(3) | x(4) | |
|---|---|---|---|---|
y(1) | z(1,1) | z(1,2) | z(1,3) | z(1,4) |
y(2) | z(2,1) | z(2,2) | z(2,3) | z(2,4) |
y(3) | z(3,1) | z(3,2) | z(3,3) | z(3,4) |
コマンド ラインで関数 fit を使用して曲面近似を行う場合、データが表形式であれば関数 prepareSurfaceData を使用します。
参考
fit | prepareSurfaceData | prepareCurveData
関連するトピック
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)