anova
説明
作成
構文
説明
aov = anova(tbl,responseVarName)tbl の変数を因子および応答データとして使用します。引数 responseVarName で、応答データが格納された変数を指定します。
aov = anova(tbl,formula)formula の項では、tbl の変数名のみを使用します。
aov = anova(___,Name=Value)
入力引数
y — 応答データ
行列 | 数値ベクトル
応答データ。行列または数値ベクトルとして指定します。
yが行列の場合、anovaはyの各列を 1 因子 ANOVA の個別の因子の値として扱います。この形式では、各列の母集団平均が等しいかどうかが評価されます。この設計は、各グループに均等に分割されたデータに対して 1 因子 ANOVA を実行する場合 (平衡型 ANOVA) に使用します。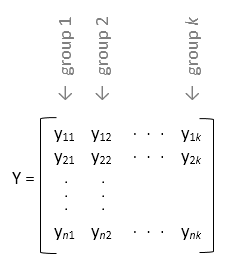
yが数値ベクトルの場合、入力引数factorsまたはtblも指定しなければなりません。1 因子 ANOVA の場合、factorsは、各要素がyの対応する要素の因子の値を表す文字ベクトルの cell 配列またはベクトルです。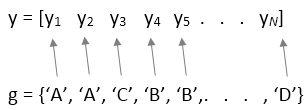
多因子 ANOVA の場合、
factorsは、各 cell が個別の因子として扱われるベクトルの cell 配列です。あるいは、多因子 ANOVA の場合は、各変数が個別の因子として扱われる tabletblを指定できます。この設計は、2 因子 ANOVA または多因子 ANOVA を実行する場合、あるいは因子の値がyの異なる数の観測値に対応する場合 (不平衡な ANOVA) に使用します。
メモ
関数 anova は、y の NaN 値、<undefined> 値、空の文字、空の string を無視します。factors または tbl に NaN 値、<undefined> 値、空の文字、空の string が格納されている場合、関数は y の対応する観測値を無視します。関数で空または NaN の値を無視した後の観測値の数がそれぞれの因子の値で同じであれば、ANOVA は平衡型になります。それ以外の場合、関数は不平衡な ANOVA を実行します。
データ型: single | double
factors — 因子と因子の値
数値ベクトル | logical ベクトル | categorical ベクトル | string ベクトル | 文字ベクトル | ベクトルの cell 配列
ANOVA の因子と因子の値。数値ベクトル、logical ベクトル、categorical ベクトル、string ベクトル、文字ベクトル、またはベクトルの cell 配列として指定します。因子と因子の値は、それぞれグループ化変数およびグループ名と呼ばれることもあります。
1 因子 ANOVA の場合、factors は、各要素が y の同じ位置にある観測値の因子の値を表す文字ベクトルのベクトルまたは cell 配列です。関数 anova は、ANOVA の実行時に y の観測値を因子の値ごとにグループ化します。factors の長さは y の長さと同じでなければなりません。
2 因子 ANOVA または多因子 ANOVA の場合、factors は、各 cell が異なる因子に対応するベクトルの cell 配列です。各ベクトルに対応する因子の値が格納され、その長さは y と同じでなければなりません。因子の値は y の観測値にインデックスで関連付けられます。
factors に NaN 値が含まれている場合、anova は y の対応する観測値を無視します。
因子の詳細については、グループ化変数を参照してください。
メモ
factors または tbl に NaN 値、<undefined> 値、空の文字、空の string が格納されている場合、関数 anova は y の対応する観測値を無視します。関数で空または NaN の値を無視した後の観測値の数がそれぞれの因子の値で同じであれば、ANOVA は平衡型になります。それ以外の場合、関数は不平衡な ANOVA を実行します。
例: [1,2,1,3,1,...,3,1]
例: ["white","red","white",...,"black","red"]
例: school=["Springfield","Springfield","Springfield","Arlington","Springfield","Arlington","Arlington"]; monthnumber=[6,12,1,9,4,6,2]; factors={school,monthnumber};
データ型: single | double | logical | categorical | char | string | cell
tbl — 因子、因子の値、および応答データ
テーブル
因子、因子の値、および応答データ。table として指定します。tbl の変数には、数値ベクトル、logical ベクトル、categorical ベクトル、文字ベクトル、string 要素、または文字の cell 配列を格納できます。tbl を指定する場合、応答データ y、responseVarName、または formula も指定しなければなりません。
yで応答データを指定する場合、table 変数は ANOVA の因子のみを表します。tblの変数の因子の値は、yの同じ位置にある観測値に対応します。tblの行数はyの長さと同じでなければなりません。tblにNaN値が含まれている場合、anovaはyの対応する観測値を無視します。yを指定しない場合は、入力引数responseVarNameまたはformulaを使用して、tblのどの変数に応答データが格納されているかを示さなければなりません。名前と値の引数FactorNamesを使用して、ANOVA で使用するtblの因子のサブセットを選択することもできます。関数anovaは、tblの因子変数の値を同じ行の応答データに関連付けます。
メモ
factors または tbl に NaN 値、<undefined> 値、空の文字、空の string が格納されている場合、関数 anova は y の対応する観測値を無視します。関数で空または NaN の値を無視した後の観測値の数がそれぞれの因子の値で同じであれば、ANOVA は平衡型になります。それ以外の場合、関数は不平衡な ANOVA を実行します。
例: mountain=table(altitude,temperature,soilpH); anova(mountain,"soilpH")
データ型: table
responseVarName — 応答データの名前
string スカラー | 文字ベクトル
応答データの名前。string スカラーまたは文字ベクトルとして指定します。responseVarName は、tbl のどの変数に応答データが格納されているかを示します。responseVarName を指定する場合、入力引数 tbl も指定しなければなりません。
例: "r"
データ型: char | string
formula — ANOVA モデル
string スカラー | 文字ベクトル
ANOVA モデル。ウィルキンソンの表記法による string スカラーまたは文字ベクトルとして指定します。anova では、かっことコンマを使用した入れ子になった因子の指定が formula でサポートされます。たとえば、formula に項 f1(f2) を含めることで、因子 f1 が因子 f2 の内部で入れ子になっていることを指定できます。f1 が 2 つの因子 f2 と f3 の内部で入れ子になっていることを指定するには、項 f1(f2,f3) を含めます。formula を指定する場合、tbl も指定しなければなりません。
例: "r ~ f1 + f2 + f3 + f1:f2:f3"
例: "MPG ~ Origin + Model(Origin)"
データ型: char | string
オプションの引数のペアを Name1=Value1,...,NameN=ValueN として指定します。ここで Name は引数名、Value は対応する値です。名前と値の引数は他の引数の後ろにする必要がありますが、ペアの順序は関係ありません。
例: anova(factors,y,CategoricalFactors=[1 2],FactorNames=["school" "major" "age"],ResponseName="GPA") は、factors の最初の 2 つの因子をカテゴリカルとして指定し、因子の名前を "school"、"major"、および "age" と指定し、応答変数の名前を "GPA" と指定します。
プロパティ
オブジェクト関数
boxchart | 分散分析 (ANOVA) のボックス チャート (箱ひげ図) |
groupmeans | 分散分析 (ANOVA) の平均応答推定 |
multcompare | 分散分析 (ANOVA) の平均の多重比較 |
plotComparisons | 分散分析 (ANOVA) の平均の多重比較についての対話型プロット |
stats | 分散分析 (ANOVA) の表 |
varianceComponent | 分散分析 (ANOVA) の分散成分推定 |
例
アルゴリズム
ANOVA では、応答データの変動全体を次の 2 つの成分に分割します。
ANOVA モデルで記述される因子データと応答データの関係における変動。この変動は回帰二乗和 (SSR) と呼ばれます。SSR は方程式 で表されます。ここで、n は標本の観測値の数、 は観測値 i の予測値、 は標本平均です。
ANOVA モデルの誤差項によるデータの変動。これは誤差二乗和 (SSE) と呼ばれます。SSE は方程式 で表されます。ここで、 は観測値 i の値です。
上記の分割に基づいて、二乗総和 (SST) は次のように表されます。
関数 anova は、その項を比較モデルに追加した場合の SSE の減少を測定することにより、ANOVA モデルの項の二乗和 () を計算します。比較モデルは aov.SumOfSquaresType で与えられます (詳細については SumOfSquaresType を参照)。
ANOVA では、SSE と を使用して F 検定を実行します。カテゴリカルの主効果についての帰無仮説は、項の係数がすべてのグループで同じであることです。連続する項と交互作用項の帰無仮説は、項の係数がゼロであることです。係数がゼロであるということは、その項の値が応答データに影響を与えないことを意味します。F 統計量は次のように計算されます。
上記の式で、 は項の自由度、 は誤差の自由度、 と はそれぞれ項と誤差の平均二乗です。
関数 anova は、モデル項と誤差の行をもつ成分 ANOVA 表を表示します。ANOVA 表の列は次のとおりです。
| 列 | 定義 |
|---|---|
SumOfSquares | 二乗和 |
DF | 自由度 |
MeanSquares | 平均二乗 (比率 SumOfSquares/DF) |
F | F 統計量 (ソースの平均二乗と誤差の平均二乗の比率) |
pValue | p 値 (帰無仮説のもとで計算される F 統計量が検定統計量の計算値より大きい値になる確率)。anova では、F 分布の cdf からこの確率が導き出されます。 |
参照
[1] Wackerly, D. D., W. Mendenhall, III, and R. L. Scheaffer. Mathematical Statistics with Applications, 7th ed. Belmont, CA: Brooks/Cole, 2008.
[2] Dunn, O. J., and V. A. Clark Hoboken. Applied Statistics: Analysis of Variance and Regression. NJ: John Wiley & Sons, Inc., 1974.
バージョン履歴
R2022b で導入
参考
anova | anovan | anova2 | anova1 | 多因子 ANOVA | 1 因子 ANOVA | 2 因子 ANOVA
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)